The Vantage Journey
Vantage didn’t start as a multi-backend entity framework. It started as a weekend experiment to see if Rust could build SQL queries without feeling like Rust.
This page walks you through each release — what changed, why it mattered, and how the API evolved from raw Postgres queries to a universal persistence layer.
- 0.0 — “DORM” (April–November 2024)
- 0.1 — Vantage is born (December 2024)
- 0.2 — Entity Framework & MDA (February 2025)
- 0.3 — The Great Separation (July–October 2025)
- 0.4 — The Type System Rewrite (November 2025–April 2026)
- 0.5 — The Vista Era (May–June 2026)
- 0.6 — Hardening (June 2026)
- The bigger picture
graph LR
D[0.0 DORM] -->|rename| V1[0.1 Vantage]
V1 -->|entity framework| V2[0.2 MDA]
V2 -->|crate split| V3[0.3 UI Adapters]
V3 -->|type rewrite| V4[0.4 Type System]
V4 -->|universal handle| V5[0.5 Vista]
V5 -->|hardening| V6[0.6 Robustness]
style D fill:#555,color:#fff
style V1 fill:#4a7c59,color:#fff
style V2 fill:#2d6a8f,color:#fff
style V3 fill:#8f5a2d,color:#fff
style V4 fill:#7c2d8f,color:#fff
style V5 fill:#2d8f6a,color:#fff
style V6 fill:#8f2d4a,color:#fff
0.0 — “DORM” (April–November 2024)
The project was originally called DORM — the Dry ORM. It was Postgres-only, monolithic, and proudly opinionated. Everything lived in one crate.
The core idea was already there: Data Sets. Instead of loading records eagerly, you describe what you want and let the framework figure out the query.
#![allow(unused)]
fn main() {
let clients = Client::table(); // Table<Postgres, Client>
let paying = clients.with_condition(
clients.is_paying_client().eq(&true)
);
let orders = paying.ref_orders(); // Table<Postgres, Order>
for order in orders.get().await? {
println!("#{} total: ${:.2}", order.id, order.total as f64 / 100.0);
}
}Behind this innocent-looking code, DORM generated a single SQL query with subqueries, joins, and soft-delete filters — all derived from model definitions:
SELECT id,
(SELECT name FROM client WHERE client.id = ord.client_id) AS client_name,
(SELECT SUM((SELECT price FROM product WHERE id = product_id) * quantity)
FROM order_line WHERE order_line.order_id = ord.id) AS total
FROM ord
WHERE client_id IN (SELECT id FROM client WHERE is_paying_client = true)
AND is_deleted = false
No hand-written SQL. No query strings. The framework composed everything from relationship
definitions and table extensions like SoftDelete.
Early commits show a battle with Rust’s borrow checker — the infamous “lifetime hell.”
The solution came on April 28: switching to Arc for shared ownership. This unlocked
clonable data sources and composable table references that define the framework to this day.
Milestones
| Date | What happened |
|---|---|
| Apr 11 | First commit — queries, expressions, SQLite binding |
| Apr 18 | Insert/delete support, first Postgres tests |
| Apr 28 | Arc adoption — escaped lifetime hell |
| May 14 | Query::Join implemented |
| May 25 | has_one, has_many, relationship traversal |
| May 26 | Bakery model example — all entities defined |
0.1 — Vantage is born (December 2024)
On December 12, the framework was renamed from DORM to Vantage and published to crates.io for the first time. The API stayed the same — this was a branding milestone, not an architectural one.
A vantage point gives you a clear view of the landscape below. The framework gives you a clear view of your data — no matter where it lives or how complex the relationships are.
The same month brought the first Axum integration (bakery_api), proving that data sets could drive
REST endpoints naturally:
#![allow(unused)]
fn main() {
async fn list_orders(
client: axum::extract::Query<OrderRequest>,
pager: axum::extract::Query<Pagination>,
) -> impl IntoResponse {
let orders = Client::table()
.with_id(client.client_id.into())
.ref_orders();
let mut query = orders.query();
query.add_limit(Some(pager.per_page));
Json(query.get().await.unwrap())
}
}Tags v0.1.0 and v0.1.1 were published the same day. SQLx data source landed 11 days later.
0.2 — Entity Framework & MDA (February 2025)
Version 0.2 repositioned Vantage as a full Entity Framework with Model-Driven Architecture. The README doubled in size. The vision expanded from “clever query builder” to “how enterprises should structure business logic.”
The key insight: entities aren’t just database rows. They’re business objects that might live in SQL, NoSQL, a REST API, or a message queue — and your code shouldn’t care which.
#![allow(unused)]
fn main() {
impl Client {
fn table() -> Table<Client, Oracle> { /* ... */ }
fn registration_queue() -> impl Insertable<Client> { /* Kafka */ }
fn admin_api() -> impl DataSet<Client> { /* REST */ }
fn read_csv(file: String) -> impl ReadableDataSet<Client> { /* CSV */ }
}
}A developer calling Client::registration_queue().insert(id, client).await doesn’t
need to know it’s Kafka underneath. The SDK hides the transport — only the entity
contract matters.
This release also introduced the idea of struct projection — using different Rust types against the same data set to control which fields get queried:
#![allow(unused)]
fn main() {
struct MiniClient { name: String }
struct FullClient { name: String, email: String, balance: Decimal }
// Only fetches `name` from the database
let name = clients.get_id_as::<MiniClient>(42).await?.name;
}The monolith was getting heavy, though. Everything still lived in one crate, and adding a new database meant touching core code.
0.3 — The Great Separation (July–October 2025)
Version 0.3 broke the monolith into dedicated crates and bet heavily on SurrealDB as the primary backend. The trait-based architecture that defines Vantage today was born here.
One crate became many: vantage-expressions, vantage-table, vantage-dataset,
vantage-surrealdb, surreal-client, vantage-config, vantage-ui-adapters — each
with a focused responsibility.
Table definitions moved from static initialization to a builder pattern:
#![allow(unused)]
fn main() {
// 0.2 — static, Postgres-only
Table::new_with_entity("bakery", postgres())
.with_id_column("id")
.with_column("name")
.with_many("clients", "bakery_id", || Box::new(Client::table()))
// 0.3 — builder, any datasource
Table::<SurrealDB, Client>::new("client", ds.clone())
.with_id_column("id")
.with_column("name")
.with_column("email")
.with_many("orders", "client_id", || Client::order_table())
}Field accessors now return Expression instead of column objects — making them composable across
query builders:
#![allow(unused)]
fn main() {
// Build conditions from expressions
let active = clients.is_paying_client().eq(true);
let big_spenders = clients.balance().gt(1000);
let query = clients.with_condition(active).with_condition(big_spenders);
}The AnyTable type-erasure system arrived, enabling generic code that works with any
datasource:
#![allow(unused)]
fn main() {
let tables: Vec<AnyTable> = vec![
AnyTable::new(Client::table()), // SurrealDB
AnyTable::new(Product::table()), // SQLite
];
for table in &tables {
println!("{}: {} records", table.name(), table.count().await?);
}
}This release culminated with UI adapters for six frameworks — egui, GPUI, Slint, Tauri, Ratatui,
and Cursive — all driven by the same AnyTable interface.
The same bakery model powered a native desktop app (GPUI), a web app (Tauri), a terminal dashboard (Ratatui), and three more — without changing a single line of business logic.
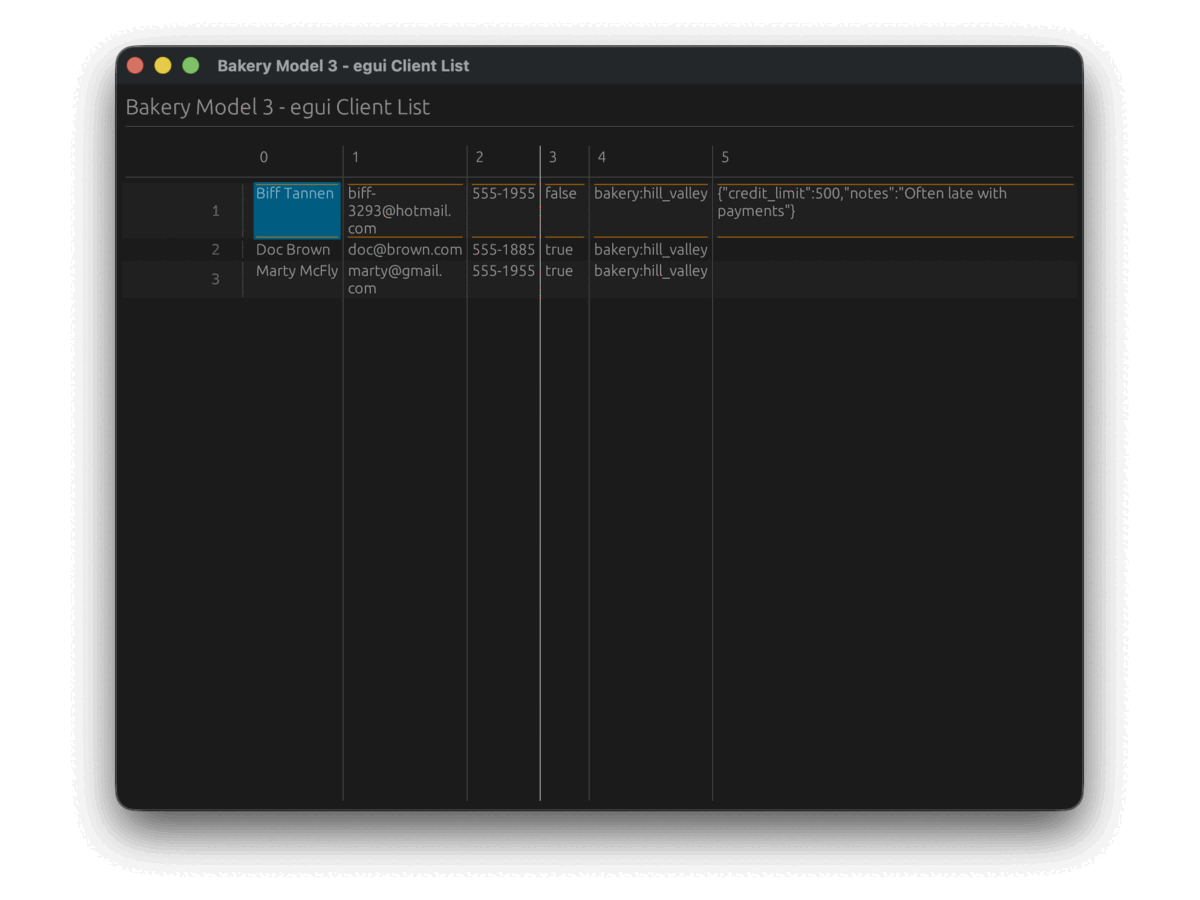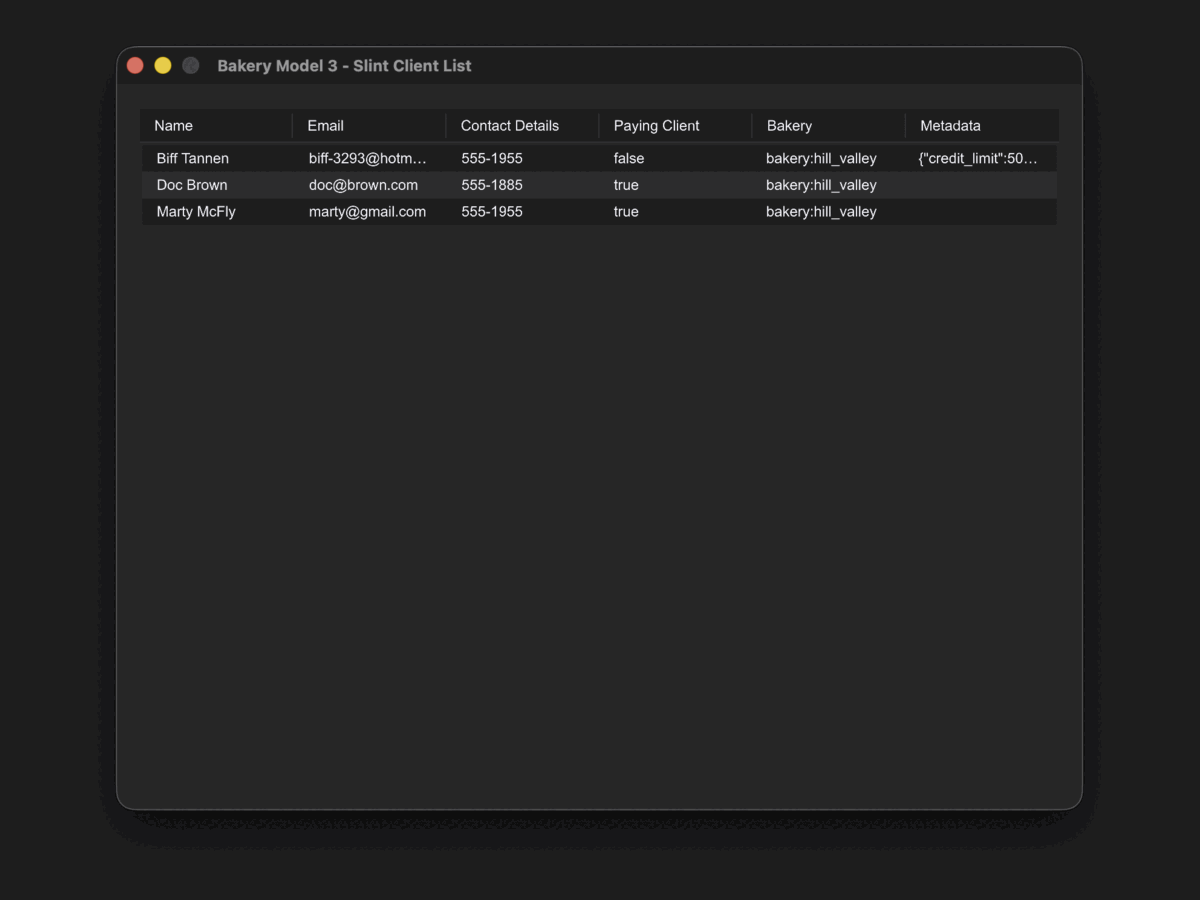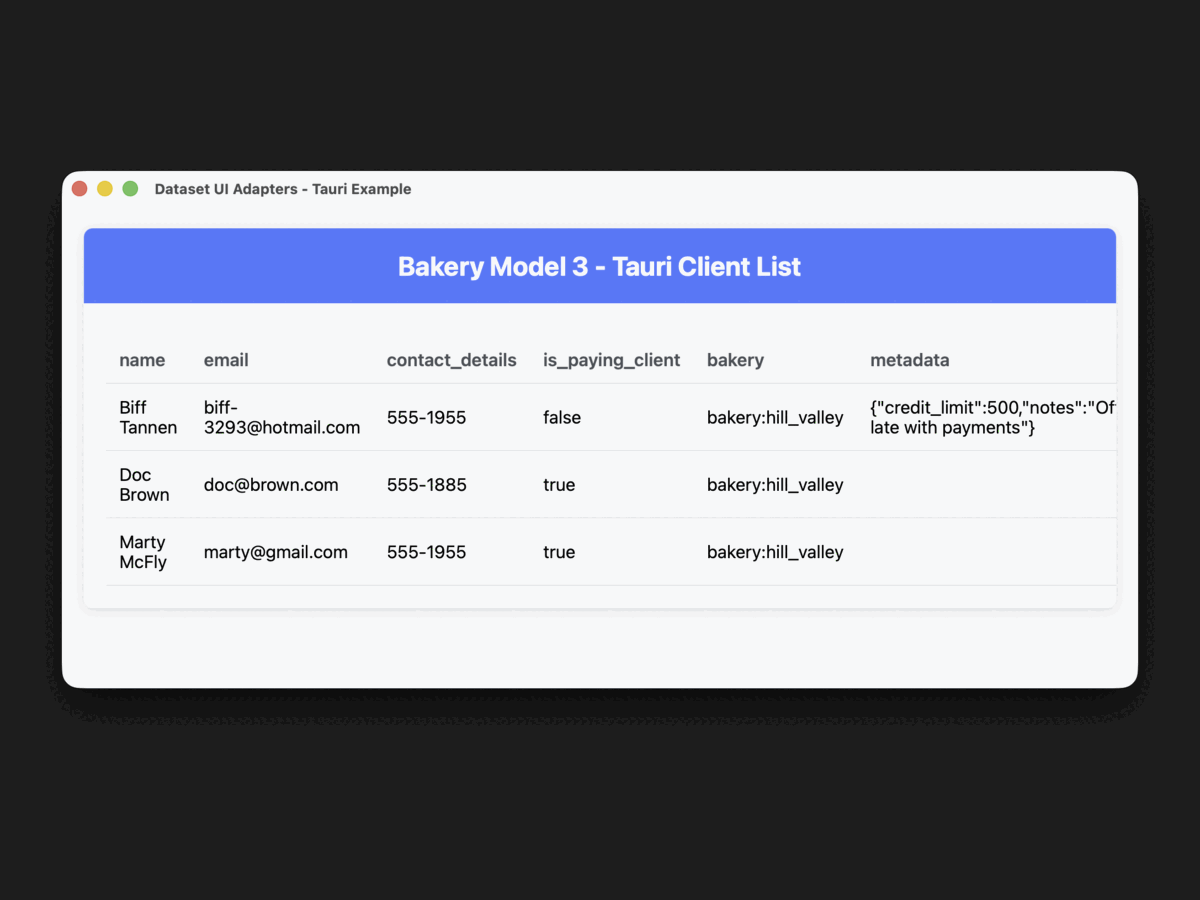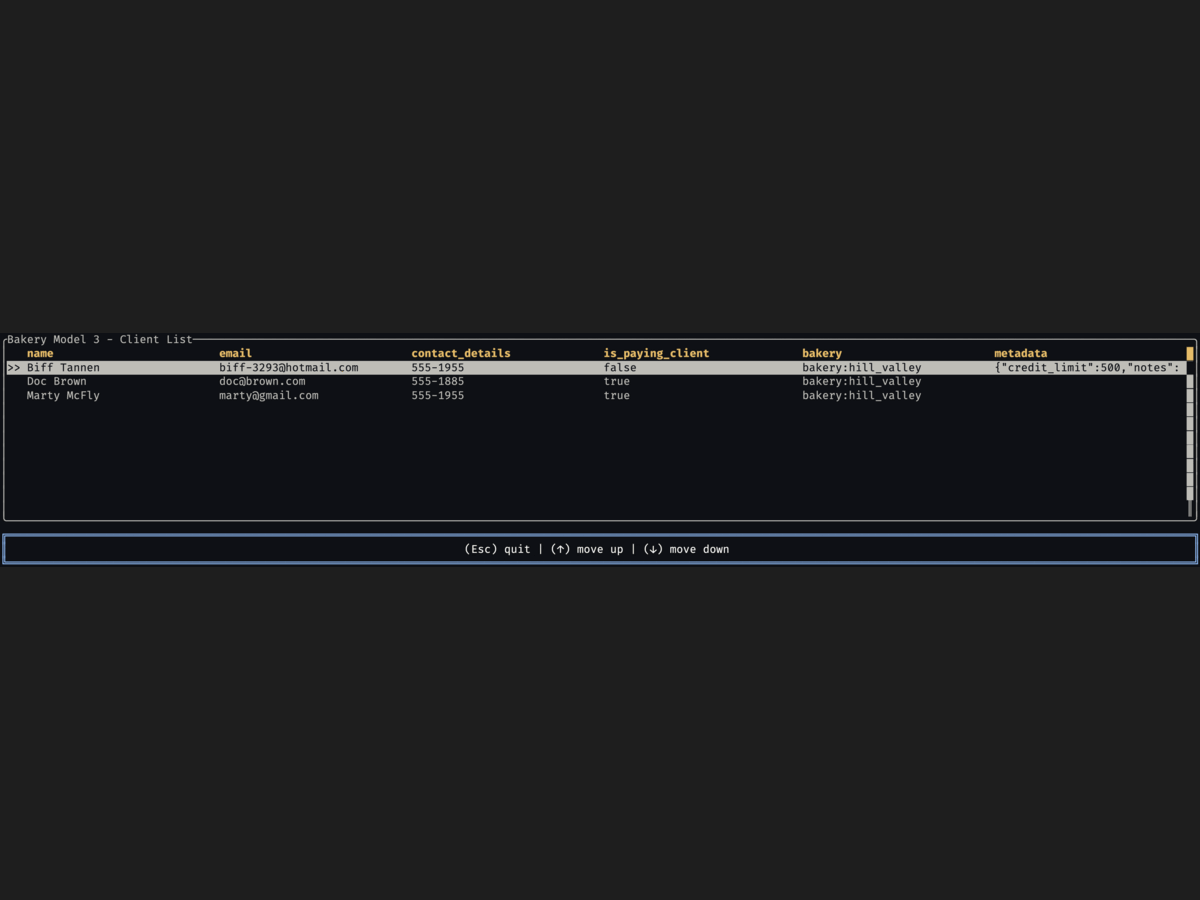
0.4 — The Type System Rewrite (November 2025–April 2026)
Version 0.4 rewrites the type system from the ground up. Custom types per datasource, CBOR
protocol, 7 persistence backends (SurrealDB, Postgres, MySQL, SQLite, MongoDB, CSV, REST API),
ActiveEntity / ActiveRecord patterns, typed columns, unified error handling, and a progressive
trait model where each persistence only implements what its engine supports.
0.5 — The Vista Era (May–June 2026)
Version 0.4 made the type system precise. Version 0.5 asks the next question: how does code that
doesn’t know your entity type talk to your data? A CLI that lists any table, a web admin that draws
forms from a YAML schema, a UI data grid pointed at whatever you give it — none of them know your
Product struct.
0.4’s answer was AnyTable: type-erasure that funnelled everything through JSON. 0.5 replaces it
with Vista — a universal, schema-bearing data handle. A Vista wraps any typed Table<DB, E>,
erases both backend and entity, and carries its own schema (columns, references, capabilities) while
delegating execution to a per-driver TableShell.
#![allow(unused)]
fn main() {
// Wrap any typed table — SQLite, MongoDB, AWS, all the same shape
let vista = SqliteVistaFactory::new(db).from_table(Product::table(db.clone()))?;
// Everything is now runtime introspection — no generics, no entity type
for name in vista.get_column_names() {
let col = vista.get_column(name).unwrap();
println!("{}: {}", col.name, col.original_type);
}
let mut v = vista.clone();
v.add_condition_eq("category_id", 1.into())?; // driver translates to native condition
v.add_search("tart")?; // fans across SEARCHABLE columns
v.add_order("price", SortDirection::Descending)?;
let rows = v.fetch_page(1).await?;
}Where AnyTable narrowed every value to serde_json::Value, Vista carries
ciborium::Value end to end — preserving integer-vs-float, binary
blobs, and precise decimals. JSON conversion happens only at the boundary, when you actually need it
(an HTTP response, say).
The AnyTable carrier was deleted outright in vantage-table 0.5.2 — type erasure now lives one
layer up, in Vista. That decommission is what the 0.5 version bump marks.
Capabilities — the explicit contract
Not every backend can do everything. A CSV file can’t sort server-side; DynamoDB can only order by its sort key; a REST API may paginate by cursor but not by page number. Vista makes this explicit with a struct of capability flags, and each driver declares exactly what it supports:
#![allow(unused)]
fn main() {
let caps = vista.capabilities();
if caps.can_search { v.add_search("query")?; }
if caps.can_fetch_page { /* random-access pager */ } else { /* load-more button */ }
}Calling a method the driver doesn’t advertise returns an Unsupported error — never a silent
match-all, never a panic. UI adapters branch on these flags to decide which controls to render.
Config-driven: YAML specs and Rhai scripting
A Vista no longer needs a hand-written Rust definition. Tables, columns, and relations can be
declared in a YAML spec (VistaSpec) and loaded by the driver’s factory. For anything YAML
can’t express — vendor-specific expressions, derived sources, scripted reference traversal — there’s
an optional Rhai DSL that compiles to native queries:
#![allow(unused)]
fn main() {
let users = table("users").alias("u");
select()
.from(users)
.expression(users["name"])
.where(users["age"] >= 18)
.order_by(users["name"], "asc")
}The same script renders dialect-correct SQL for SQLite, Postgres, and MySQL — automatic identifier
quoting, date_format() mapping to strftime/TO_CHAR/DATE_FORMAT, group_concat() becoming
GROUP_CONCAT/STRING_AGG. SurrealDB gets its own vocabulary (graph traversal, RELATE, record
ids). YAML stays the primary format; Rhai is the targeted, serializable escape hatch.
Contained relations and nested writes
Embedded objects and arrays — an order’s lines, a row’s JSON column — now surface as a fully
editable sub-Vista. SurrealDB backs them with native nested objects; SQL backends store them as
JSON columns and patch the host column on writeback. And insert_value learned to walk relations:
hand it a record whose keys name a relation and it sequences the writes, stamping foreign keys
automatically.
Diorama — caching, events, and reactive views
The biggest new subsystem is vantage-diorama — a layer that sits between a Vista and whatever
consumes it. Three concepts:
- Lens — long-lived shared infrastructure: a cache backend, lifecycle callbacks, refresh policy. Built once per application.
- Dio — a Vista bound to a Lens. Owns the cache table, a write queue, an event bus, and a refresh task.
- Scenery — a reactive view onto a Dio (ordered tables, individual records, aggregates) that a UI binds to.
#![allow(unused)]
fn main() {
let lens = Arc::new(
Lens::new()
.cache_at("./cache.redb")
.on_start(|dio| { let dio = dio.clone(); async move {
let rows = dio.master().list_values().await?;
dio.cache().insert_values(rows).await?;
Ok(())
}})
.refresh_every(Duration::from_secs(300))
.build()?,
);
let products = lens.make_dio(products_vista).await?;
let mut v = products.vista(); // facade: reads from cache, writes through the queue
}Diorama caches the full dataset locally, so a read-only CSV Vista that can’t paginate, sort, or search server-side becomes one that can — the consumer sees a richer Vista than the backend actually supports. Two-pass progressive loading renders a cheap list immediately and hydrates expensive per-row detail lazily as rows scroll into view.
More backends, more reach
0.5 also widened the backend roster around the Vista abstraction: redb (embedded key-value
store), AWS (DynamoDB and friends, all returning Vistas directly), a Cmd source that turns a
shell script into a queryable table, and an API pool. Cross-persistence reference traversal —
categories in Postgres, products in MongoDB — moved out of Vista and into
vantage-vista-factory’s VistaCatalog, keeping each Vista strictly single-backend.
The getting-started guide was rewritten around these concepts — chapters on Vista, Dio & Lens, and Scenery build a CLI up from a single SQLite query to a reactive, cached, multi-backend handle.
0.6 — Hardening (June 2026)
If 0.5 was about reach, 0.6 is about trust. The release is a coordinated, workspace-wide sweep with a single theme: no panics, no silent failures. Every path that could abort the process deep inside a write, or quietly return a wrong answer, was made fallible and explicit.
- Serialization is fallible. A new
TryIntoRecordtrait replaces the infallible blanket: a failingSerialize(non-string map keys, an out-of-range number) now becomes a recoverable error instead of a process abort mid-write.Entitywrite paths (insert/replace/patch) propagate it. - No silent zeros.
get_countunwraps the common[{"count": N}]shape and surfaces unrecognized result shapes as errors instead of returning0. - No silent match-all. Search on a backend that can’t search server-side (CSV, redb) returns an
Unsupportederror — never a quietly unfiltered result set. - Expression safety.
f64::IntoValuedegrades NaN/Infinity toNullinstead of panicking;Expression::preview()uses single-pass interleaving so a{}inside a rendered value can’t corrupt the output.select_columnbecame fallible. - Clearer error classification.
vantage-core’s error-kind annotators were renamed tomark_unsupported/mark_unimplemented(theis_*names are now real predicates), and trace emission was decoupled —mark_*no longer logs implicitly; chain.traced()when you want thetracing::error!event. - Security: SurrealDB identifier injection. Identifier escaping was unified into
surreal-client’s singleescape_identifierauthority and fixed for SurrealDB 3.x — a crafted⟩inside a column name could previously break out of⟨…⟩quoting and inject arbitrary SurrealQL.similarity()andtime_group()literals are now bound as parameters rather than interpolated, closing the same hole on the Rhai-exposed search path.
Alongside the hardening, 0.6 folded the standalone vantage-data-script crate into vantage-vista’s
rhai feature, added random-access windowing (fetch_window) with REST lazy-loading, and introduced
ColumnFlag::Label for status-tag display hints.
The bigger picture
Looking at the trajectory:
| Version | Core idea | Backends | Crates |
|---|---|---|---|
| 0.0 | Can Rust build SQL smartly? | Postgres | 1 |
| 0.1 | Let’s publish this | Postgres | 1 |
| 0.2 | Entity Framework for Rust | Postgres | 1 |
| 0.3 | Traits, not inheritance | SurrealDB, SQLite | 10+ |
| 0.4 | Strict types, any persistence | SurrealDB, SQLite, Postgres, MySQL, MongoDB, CSV, REST API | 20+ |
| 0.5 | A universal data handle | + redb, AWS (DynamoDB), Cmd (shell scripts) | 25+ |
| 0.6 | No panics, no silent failures | (same — hardening release) | 25+ |
What started as 16 commits in April 2024 is now 800+ commits, 300+ pull requests, and a
framework that can drive the same business logic across a dozen backends and six UI frameworks —
typed when you know the entity, universal (via Vista) when you don’t.
The destination hasn’t changed since day one: describe your data once, use it everywhere. Each version just made “everywhere” a little bigger.